Written by: Mariana Fonseca, Editorial Team, AI Growth Agent
Key Takeaways for llms.txt in 2026
- An llms.txt file is a Markdown document at the root domain that gives AI systems a structured map of authoritative pages using H1/H2 headers and descriptive link summaries.
- Best practices include hosting at the root, opening with an H1 and value proposition, grouping links by user journey, curating 10–50 links, and publishing a companion llms-full.txt file.
- llms.txt works best as part of a four-pillar headless marketing stack that includes search intelligence, AI analytics, bot tracking, and AI ranking rather than as a standalone file.
- High-performing files use specific, audience-targeted summaries, exclude thin or blocked pages, and refresh quarterly or automatically on CMS publish events to avoid staleness.
- Brands seeking compounding citation lifts across ChatGPT, Perplexity, and Google AI Mode should schedule a consultation with AI Growth Agent to implement llms.txt as part of a complete living content engine.
How llms.txt, llms-full.txt, and Schema Work Together
llms.txt is the slim index file that introduces your brand to AI agents. Mintlify’s analysis of production files reveals what makes this format effective: an H1 brand name, a short blockquote with a one-sentence product description, and H2 sections containing curated, descriptively labeled links. This structure exists to answer one question for the AI agent reading it: what the brand covers and where the best content lives for each topic.
llms-full.txt is the companion file that supplies complete Markdown content for IDE indexing and retrieval-augmented generation pipelines. Mintlify identifies this as the “Index + export” pattern used by Anthropic, Vercel, and LangGraph, where the slim llms.txt supports real-time conversational tools and llms-full.txt handles deep ingestion. Profound’s GEO research found that crawlers from OpenAI fetch llms-full.txt more frequently than llms.txt, which makes the companion file the higher-priority asset for enterprise brands targeting those surfaces.
Markdown rules are non-negotiable for llms.txt. Every link must be a standard Markdown bullet followed by a descriptive summary. Ahrefs’ implementation guidance specifies the format as: - /page.md A one-line description of what this page covers and who it is for. Generic titles like “API Reference” provide minimal signal. Specific labels like “Payments API: Charges and Payment Intents” give the AI agent the context it needs to select the right resource.
Grouping by user journey rather than site hierarchy separates high-performing files from low-performing ones. Mintlify recommends organizing content so the file directly answers what a user needs to accomplish at the moment they query an AI agent, not what the site navigation labels a section.
Exclusions matter as much as inclusions. Thin pages, login-gated content, duplicate URLs, and any page blocked in robots.txt should be omitted. Andreas Welsch frames robots.txt, llms.txt, llms-full.txt, and schema as complementary layers: robots.txt for access control, llms.txt and llms-full.txt for representation, and schema for interpretation. A URL that robots.txt blocks cannot be rescued by llms.txt inclusion.
Schema, MCP, and bot tracking form the infrastructure that makes llms.txt meaningful. The State of Martech 2026 report groups schema markup, llms.txt files, and MCP servers as three distinct mechanisms operating at different layers of the stack to make brand infrastructure legible to AI systems. Schema tells bots what content means. MCP endpoints expose brand-controlled content directly to AI systems. Bot tracking shows which agents are reading the file and citing the content. Without all three, llms.txt is a map with no roads behind it. Provisioning this complete stack requires coordination across multiple technical systems that must work together from day one.
Why llms.txt Matters in the 2026 AI Search Landscape
In 2026, agentic technical SEO determines whether a brand exists in AI-generated answers. Google’s AI Mode crossed 1 billion monthly users within its first year, with queries more than doubling every quarter since launch. Information agents that monitor the web continuously are rolling out this summer for Google AI Pro and Ultra users. Every one of those surfaces consumes content the same way: it reads, cites, and acts on whatever the model can find and trust.
Zero-click behavior makes narrative control the central marketing problem. Roughly 83% of people report skepticism toward AI answers, yet only about 8% click through to verify them. For most users, the AI answer functions as the answer. Brands that are not cited in that answer do not exist in the conversation.
llms.txt fits inside a four-pillar data foundation that governs what AI surfaces say about a brand. Search Intelligence maps the full traditional search landscape, covering positioning, competition, and search volume across seed terms and long-tail queries. This foundation informs AI Analytics, which tracks brand value and consumer behavior across the full journey, from external AI-tool queries through content consumption and sentiment. Bot Tracking then records every bot interaction, including AI training sweeps and citation passes, so brands can see which agents are reading their content and when. Finally, AI Ranking monitors order of mention and citation context in AI answers, which replace the static ranked list as the new leaderboard.
llms.txt without these four pillars becomes a file with no feedback loop. A brand cannot know whether the file is being read, which agents are fetching it, or whether the citations it earns are improving without bot tracking and AI ranking data running alongside it.
Three Ways Brands Implement llms.txt
Three implementation paths exist for brands building an llms.txt strategy, and they produce materially different outcomes.
Manual file creation is the starting point for most teams. A developer writes a Markdown file, hosts it at the root domain, and updates it when they remember to. Guidance on maintaining llms.txt for AI agents recommends a quarterly review as the minimum cadence, and notes that if a team cannot commit to quarterly updates, deleting the file is cleaner than maintaining a stale one. Manual creation works for small sites with stable content. It breaks down for any brand publishing more than a handful of pages per month.
Index-plus-export patterns represent the next level of sophistication. Webflow shipped three Beta API endpoints in October 2025 that allow Enterprise customers to manage llms.txt files programmatically, with a recommended integration pattern using a webhook on collection_item_published to trigger regeneration of llms.txt content followed by a PATCH update, which keeps the file synchronized with published CMS changes without manual intervention. Mintlify and Fern automatically regenerate llms.txt and llms-full.txt whenever documentation changes, while Yoast SEO on WordPress performs weekly regeneration via WordPress cron jobs. This pattern solves the drift problem but still leaves the brand responsible for the authoritative content behind the file.
Full headless marketing automation is the approach that produces compounding citation lifts. This approach integrates llms.txt and llms-full.txt generation into a living content engine that maps the full universe of seed terms and long-tail queries, publishes authoritative content against each one, refreshes that content quarterly, and reports incremental visibility week over week. AI Growth Agent clients average more than 12,000 additional AI citations and mentions across the first twelve weeks, a result that manual file creation and index-plus-export patterns alone cannot produce because they do not address the authoritative content the AI surfaces are actually citing.
How to Judge Whether Your llms.txt Approach Is Enough
File structure quality is the first variable. AI Rank Lab’s analysis of 500 sites found that citation gains were larger when llms.txt contained highly specific summary sections that clearly described audience, differentiation, topic coverage, authority signals, and action context. Structure is not cosmetic. It is the primary driver of whether the file produces citation lift.
Descriptive summaries are the mechanism behind that finding. Devanshu, AI Search Optimization Expert at AI Rank Lab, states: “A generic two-sentence description gives minimal benefit. A specific, audience-targeted summary with authority signals and clear differentiation drives meaningful citation improvement across the LLMs that support it.”
Page listing depth determines long-tail citation performance. Sites that included well-described page listings in llms.txt tended to achieve greater citation improvement on long-tail queries.
llms-full.txt usage is non-negotiable for enterprise brands. The slim index file supports conversational tools. The full file handles IDE indexing and RAG ingestion. Brands that publish only llms.txt are invisible to the ingestion pipelines that train the next generation of models on their content.
Update cadence determines whether the file compounds or decays. AirOps research found that pages not updated within three months are three times more likely to lose AI citation visibility. A quarterly refresh is the floor. Automated regeneration on CMS publish events is the ceiling.
Content quality behind the file is the factor most brands underweight. Sites combining llms.txt implementation with content quality improvements can achieve greater citation improvement than sites that added llms.txt alone. The file is a map. The authoritative content is the destination. Without the destination, the map earns nothing.
Typical Implementation Stages for Enterprise Teams
Universe mapping is the first stage. Before writing a single line of llms.txt, a brand needs a complete picture of its seed terms and the long-tail queries beneath them. AI Growth Agent maps this universe using real-time Google and ChatGPT data as the objective function, identifying which queries are worth pursuing and which content gaps represent the highest citation opportunity. A new account typically starts with 300 to 400 queries and expands as it captures more of the universe.
Content grouping by user journey translates the universe map into llms.txt structure. H2 sections correspond to the stages a buyer moves through, not the categories a site architect invented. A brand selling adjustable beds groups content under sections like “Sleep Health Research,” “Financing and Purchasing,” and “Setup and Configuration,” because those are the tasks a buyer is completing when they query an AI agent.
Before-and-after llms.txt structure illustrates the difference between a low-performing and high-performing file. A low-performing file looks like this:
# Brand Name ## Products - /products Overview of our product line ## Blog - /blog Our latest articles
A high-performing file looks like this:
# Brand Name > The leading platform for [specific outcome] for [specific audience]. ## Getting Started - /guide/quickstart.md Step-by-step setup for [audience] deploying [product] for the first time - /guide/integrations.md How to connect [product] with [specific tools] in under 15 minutes ## Core Use Cases - /use-cases/enterprise.md How enterprise teams use [product] to reduce [specific pain] by [specific outcome] - /use-cases/compliance.md Compliance requirements [product] satisfies for [regulated industry]
The second file gives an AI agent the audience, the differentiation, the action context, and the authority signal for every link. The first gives it nothing a model cannot infer from the URL alone, which limits citation lift.
Schema and MCP integration runs in parallel with llms.txt publication. Andreas Welsch recommends establishing a review cadence of at least once per quarter to avoid significant drift between llms.txt, llms-full.txt, and schema. AI Growth Agent provisions the full schema suite, Blog MCP, OpenAI discovery via /.well-known/, and agent discovery automatically, so every article and every site ships with the complete agentic technical SEO stack live on day one.
First-week site launch is the delivery milestone. AI Growth Agent stands up a fully optimized site the client owns within the first week, with content indexing in as little as ten days.
How to Manage and Measure llms.txt Over Time
Quarterly self-healing refreshes set the maintenance standard for any brand publishing content regularly. Stale content is worse than no file, and a monthly review at minimum is recommended, paired with strategic content releases. AI Growth Agent’s living content engine handles this automatically. When the year turns, every article in a sector is refreshed, and llms.txt and llms-full.txt are regenerated to reflect the current content architecture, which eliminates the manual quarterly review burden.
Incremental visibility reporting isolates what the llms.txt implementation and the content behind it actually generated, separate from visibility the brand already had. AI Growth Agent publishes into a separate environment and reports week over week where new visibility was created, cross-referencing bot traffic, Google Search Console, and citation data. This reporting structure gives an enterprise CMO a defensible answer for the CEO every week.

Bot tracking provides the feedback loop that makes ongoing management possible. Without knowing which agents are fetching llms.txt and llms-full.txt, which pages they are crawling after the fetch, and which citations they are producing, a brand manages a file with no signal. AI Growth Agent’s WordPress plugin tracks every bot interaction, including the bot ChatGPT uses to cite sources, and surfaces that data in the reporting view alongside Google Search Console as an independent audit.
Citation context monitoring tracks order of mention and the claims a brand is cited for in AI answers. This practice replaces the old idea of a single ranking number. A brand cited first in response to “best adjustable bed retailer in Canada” holds a fundamentally different position than a brand cited fourth in a list of alternatives. Leva Sleep, after implementing AI Growth Agent’s full headless marketing stack, reached ChatGPT citation rates of over 10,000 per month and closed $40,000 to $50,000 in deals in under three weeks from buyers who discovered the brand through AI-cited content.
Risks, Limitations, and Common Mistakes
Stale files are the most common failure mode. A brand publishes llms.txt at launch, adds 200 articles over the following year, and never updates the file. The AI agent reading it gets a map of a site that no longer exists. Guidance on maintaining llms.txt for AI agents states that if a team cannot commit to quarterly review and updates, deleting the file is cleaner than maintaining a stale static file that drifts out of alignment with the live site.
Over-inclusion of thin pages dilutes the signal the file sends. Ahrefs’ implementation guidance recommends hosting the file at the root domain with 10 to 50 curated links rather than hundreds of uncurated ones. A file that lists every URL on a site tells the AI agent nothing about which pages are authoritative. Curation is the editorial judgment that makes the file useful.
Lack of descriptive summaries is the structural mistake that produces the lowest citation outcomes. AI Rank Lab’s 500-site study found that sites scoring low on specificity in their summary sections averaged only +6% citation improvement, compared to +31% for sites with highly specific, audience-targeted summaries. A URL without a description is a door with no label.
Treating llms.txt as a standalone tactic is the strategic mistake that produces the most disappointing results. AI Rank Lab states that llms.txt improves how AI systems understand and navigate a site but cannot override robots.txt blocks on AI crawlers or make thin or low-quality content citation-worthy. The file is a pointer. The authoritative content it points to is what earns the citation. Brands that publish llms.txt without investing in the content behind it are pointing AI agents at empty rooms.
Ignoring the evidence on adoption leads to misallocated effort. OtterlyAI’s 90-day experiment found that only 84 of 62,100+ AI bot visits targeted /llms.txt, representing about 0.1% of all AI bot traffic. SE Ranking’s analysis of approximately 300,000 domains found no statistically significant correlation between the presence of an llms.txt file and higher AI citation frequency. These findings do not mean llms.txt has no value. They show that it functions as one component of a stack, not the stack itself. Brands that treat it as the primary lever and neglect content quality, schema, and MCP integration will see the results the data predicts.
Summary and Decision Support for CMOs
llms.txt is a necessary component of an enterprise AI search strategy, yet it is not sufficient on its own. The file structure, descriptive summaries, exclusion discipline, llms-full.txt companion, refresh cadence, and schema and MCP integration all determine whether the file produces citation lift or sits unread at the root of a domain.
The brands generating compounding citation results in 2026 are not the ones with the neatest llms.txt formatting. They are the ones running a headless marketing stack that produces living, authoritative content across the full universe of seed terms and long-tail queries, publishes that content with the complete agentic technical SEO stack, tracks every bot interaction, and reports incremental visibility week over week. llms.txt is the index. The stack is what makes the index worth reading.
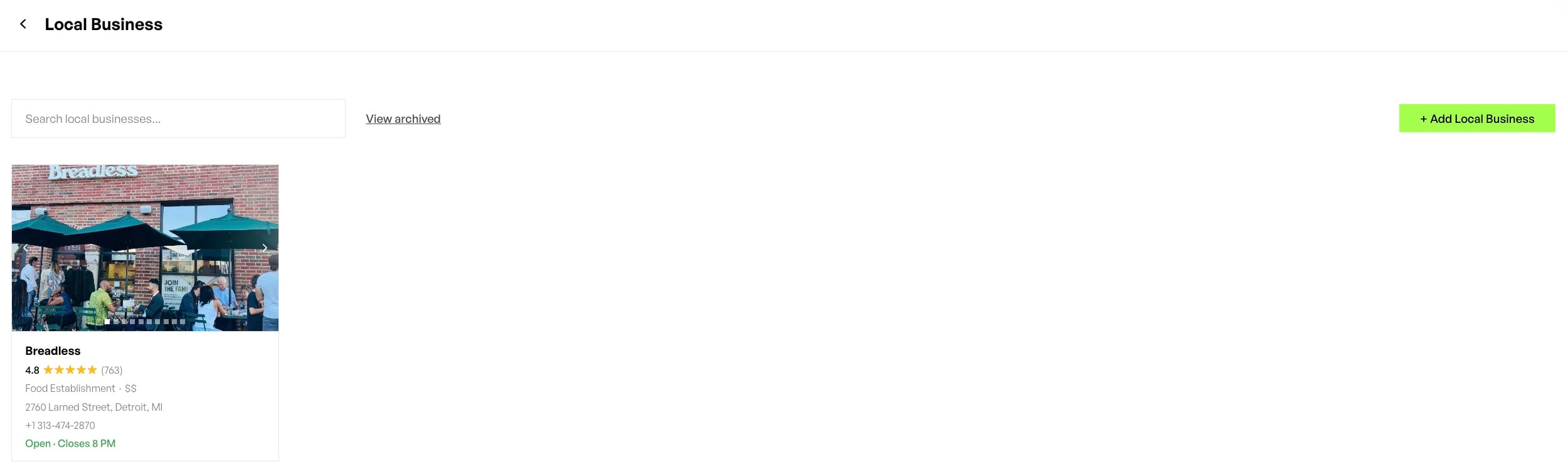
Breadless achieved a 30x lift in Google Search Console impressions over six months and is now the most recommended healthy franchise in the US ahead of CAVA, Rush Bowls, and Sweetgreen, not because it published a well-formatted llms.txt file, but because it ran a complete headless marketing engine that produced authoritative content across its full universe and gave AI surfaces the structured, validated, living content they need to cite a brand with confidence.
The decision for an enterprise CMO is not whether to publish llms.txt. The decision is whether to publish it as a standalone file that decays, or as part of a living stack that compounds. The first path checks a box. The second path delivers narrative control.
FAQ
What is the correct file structure for an llms.txt file?
An llms.txt file is a Markdown document hosted at the root of a domain (yourdomain.com/llms.txt). The correct structure opens with an H1 containing the brand or product name, followed immediately by a blockquote with a one-sentence description of what the brand does and who it serves. H2 headers then organize curated links by user journey and task, not by site navigation. Each link is a Markdown bullet followed by a descriptive one-line summary that names the audience, the differentiation, and the action context for that page. The file should contain 10 to 50 curated links. Generic titles like “Blog” or “API Reference” provide minimal signal to AI agents. Specific labels like “Franchise Development Guide: Requirements and ROI for US Operators” give the agent the context it needs to select and cite the right resource. Thin pages, login-gated content, and any URL blocked in robots.txt should be excluded.
What is llms-full.txt and when should a brand publish it?
llms-full.txt is the companion file to llms.txt. Where llms.txt is a slim index of curated links, llms-full.txt contains the complete Markdown content of a brand’s most important pages, formatted for IDE indexing and retrieval-augmented generation pipelines. Enterprise brands should publish both files. The slim index supports real-time conversational AI tools that need a fast map of a site. The full file handles the deep ingestion pipelines that train models and power agent reasoning on top of brand content. Crawlers from Microsoft and OpenAI fetch llms-full.txt more frequently than llms.txt, which makes the companion file the higher-priority asset for brands targeting those surfaces. Any brand that publishes only llms.txt is invisible to the ingestion pipelines that shape what the next generation of models knows about them.
Why does the quarterly refresh cadence matter for llms.txt?
An llms.txt file that was accurate at publication becomes a liability as the site evolves. New authoritative pages go unlisted. Retired pages remain linked. Summaries describe content that has been updated or replaced. AI agents reading a stale file get a map of a site that no longer exists, which undermines rather than supports citation accuracy. A quarterly review is the minimum cadence for any brand publishing content regularly. For brands publishing weekly, automated regeneration triggered by CMS publish events is the correct architecture. The practical rule stays simple: if a team cannot commit to quarterly updates, a deleted file is cleaner than a stale one. For enterprise brands running a headless marketing stack, the refresh cadence is automated and tied to the living content engine, so the file always reflects the current content architecture without manual intervention.
How do schema markup, MCP endpoints, and bot tracking integrate with llms.txt?
Schema markup, MCP endpoints, and llms.txt operate at different layers of the same stack. Schema tells AI bots what content means. It labels an article as an article, a product as a product, an author as an author, and a review as a review, which gives the model structured metadata it can use to evaluate authority and relevance. MCP endpoints expose brand-controlled content directly to AI systems, enabling agents to query the brand’s content programmatically rather than relying on a crawl. llms.txt provides the navigational map that tells agents which pages are authoritative and what each one covers. Bot tracking closes the feedback loop by recording which agents are fetching the file, which pages they visit after the fetch, and which citations they produce. Without bot tracking, a brand cannot know whether its llms.txt is being read, which agents are using it, or whether the citations it earns are improving. The four elements work together: schema for interpretation, MCP for direct access, llms.txt for navigation, and bot tracking for measurement. A brand that publishes llms.txt without the other three operates only one layer of a four-layer stack.