Written by: Mariana Fonseca, Editorial Team, AI Growth Agent
Key Takeaways
- The A2A protocol is an open standard hosted by the Linux Foundation that lets AI agents discover, communicate, and delegate tasks across different frameworks and platforms using standardized Agent Cards at
/.well-known/agent.json. - A2A and MCP operate at complementary layers: A2A handles agent-to-agent coordination while MCP manages agent-to-tool connections, so most enterprise architectures can deploy both protocols together.
- Agent Cards list capabilities, skills, authentication schemes, and endpoints that client agents use to discover compatible services, acquire credentials, and initiate stateful tasks through JSON-RPC 2.0 and SSE streaming.
- Brands that expose A2A-compliant endpoints with authoritative, schema-marked content become discoverable and citable by agentic search systems, while brands without compliant infrastructure remain invisible to the coordination layer.
- AI Growth Agent provides a complete A2A-compliant content engine that ships with Agent Card guidance, MCP integration, and agent-ready publishing on day one, so you can see how this infrastructure works for your brand.
How the A2A Protocol Standardizes Agent Communication
The A2A protocol standardizes communication between AI agents so they can discover capabilities, delegate tasks, exchange structured results, and coordinate work across vendors, frameworks, and organizational boundaries without exposing internal prompts, memory, or toolchains. Google Cloud launched the protocol in April 2025 and then donated it to the Linux Foundation, and IBM’s Agent Communication Protocol merged into it shortly after launch.
A2A has surpassed 150 participating organizations and reached enterprise production use within its first year. The protocol focuses on the interface layer between agents, not internal reasoning, so independently developed agents can collaborate while preserving clear security and technological boundaries.
At the technical level, the architecture follows a client-server pattern. A client agent initiates and orchestrates work, and a remote agent processes tasks through structured, stateful messaging with unique task identifiers and lifecycles. Communication runs over HTTP(S) using JSON-RPC 2.0 for structured messaging and Server-Sent Events for real-time asynchronous updates.
A2A Versus MCP: How They Work Together
MCP (Model Context Protocol), introduced by Anthropic in late 2024, standardizes how an AI agent interacts with external systems and tools, while A2A standardizes how agents discover and delegate work to other agents. The two protocols operate at different layers of the agent stack and work together cleanly.
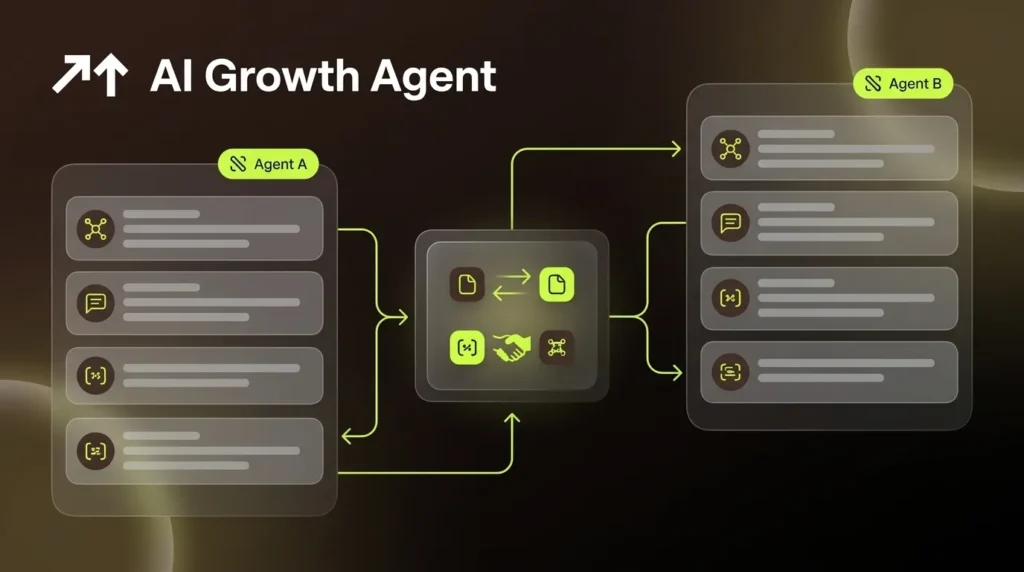
MCP uses a host-client-server model in which an AI agent connects to an MCP server that exposes tools, resources, and prompts, while A2A uses peer-to-peer communication in which agents discover each other via Agent Cards and delegate tasks directly. MCP keeps orchestration centralized inside a single agent, and A2A distributes orchestration across multiple autonomous agents.
Tools execute defined actions while agents pursue outcomes, which clarifies the boundary. MCP handles structured tool execution. A2A handles adaptive agent collaboration. In a layered architecture, a planning agent uses A2A to delegate to specialist agents, and those specialist agents use MCP to access CRM systems, policy repositories, or shipping APIs.
Rob Barton, Distinguished AI Engineer at Cisco, compares MCP to Layer-2 networking, with detailed visibility but limited scalability, and A2A to Layer-3 routing, with higher-level summarized capabilities that enable interconnection across agentic systems. Most production enterprise architectures deploy both protocols together.
Agent Cards: JSON Schema and Discovery Flow
Every A2A server must expose an Agent Card at a standardized endpoint to enable client discovery of agent capabilities, skills, supported modalities, and connection details. The following is a production-ready Agent Card example:
{"name":"content-discovery-agent","description":"Discovers and cites authoritative content for agentic search queries","url":"https://example.com/agents/content-discovery","version":"1.0.0","protocolVersion":"1.0","defaultInputModes":["text","text/plain"],"defaultOutputModes":["text","application/json"],"capabilities":{"streaming":true,"pushNotifications":true},"securitySchemes":{"oauth2":{"type":"oauth2","flows":{"clientCredentials":{"tokenUrl":"https://example.com/oauth/token","scopes":{"content:read":"Read content discovery results"}}}}},"security":[{"oauth2":["content:read"]}],"skills":[{"id":"authoritative-content-lookup","name":"Authoritative Content Lookup","description":"Retrieves validated, citation-ready content for a given query","tags":["search","citation","content-discovery"],"examples":["Find authoritative sources on adjustable bed financing options","Retrieve validated content for healthy franchise comparisons"]}]}The discovery flow follows a clear sequence. First, the client agent sends a GET request to the standardized Agent Card endpoint on the target host. Second, it parses the returned Agent Card to confirm capability compatibility, including streaming support and required authentication schemes. Third, it acquires credentials through the declared OAuth2 or API key flow. Fourth, it sends a message/send JSON-RPC 2.0 request to the agent’s url endpoint. Fifth, it receives a Task object containing a unique taskId and an initial state of submitted. Sixth, it either polls via tasks/get or subscribes to SSE updates via tasks/sendSubscribe.
Authentication, Task Management, and SSE Streaming
A2A agents declare supported authentication schemes in their Agent Cards using OpenAPI-aligned security schemes including apiKey, http (Bearer tokens), oauth2, openIdConnect, and mtls. The authentication flow has three steps: discovery of the required scheme from the Agent Card’s securitySchemes field, credential acquisition through standard external flows, and transmission of credentials in standard HTTP headers with every request.
The task lifecycle functions as the core state machine. A2A tasks are stateful and potentially long-running, with a lifecycle that includes submitted, working, input-required, auth-required, completed, failed, canceled, and rejected, and a contextId can group related tasks across multiple interactions. A minimal task request looks like this:
{ "jsonrpc": "2.0", "method": "message/send", "id": "req-001", "params": { "message": { "role": "user", "messageId": "msg-001", "contextId": "ctx-session-42", "parts": [ { "type": "text", "text": "Find authoritative content on adjustable bed financing for side sleepers" } ] } } }For SSE streaming, A2A distinguishes between TaskStatusUpdateEvent for progress and state changes and TaskArtifactUpdateEvent for intermediate or final results. When artifacts are streamed in chunks, the append and lastChunk fields indicate whether the artifact is still in progress or finished.
Production deployments require HTTPS, and TLS 1.3 or later is recommended. Clients must include an A2A-Version header with each request. For disconnected or long-running scenarios, A2A supports push notifications through client-provided webhooks in addition to SSE streaming. Rate limiting and error handling follow standard HTTP semantics, and JSON-RPC error objects return protocol-level failures.
How A2A Drives Agentic Content Discovery and Citation
The connection between A2A mechanics and brand visibility is direct. When an AI search agent receives a query, it does not search a static index. It delegates sub-tasks to specialized agents, and each agent returns structured artifacts. The agents it discovers, trusts, and cites depend on which Agent Cards exist at well-known endpoints and what authentication and capability signals those cards carry.
In a restaurant supply chain example from Google’s March 2026 Developer’s Guide, a kitchen manager agent fetches Agent Cards at runtime to discover remote supplier agents’ capabilities and routes queries dynamically, which directly supports agentic search and orchestration patterns. The same pattern applies to content discovery: an agentic search surface fetches Agent Cards, identifies which agents can answer a query authoritatively, delegates the task, and cites the returned artifacts.
This mechanism powers the shift from blue links to AI answers. Brands that expose A2A-compliant endpoints with well-structured Agent Cards, validated content, and clear authentication signals become discoverable by the agents doing the answering. Brands that do not stay invisible to the coordination layer. A2A uses context_id to maintain conversation continuity and identity across multiple agent calls, so a brand cited in one turn of an agentic session carries forward into subsequent turns.
This intersection of headless marketing and protocol mechanics now determines which brands agents recommend. Content engineered for agentic discovery, published with full schema, served in Markdown to agent crawlers, and exposed through /.well-known/ endpoints is the content that gets delegated to, cited, and recommended at scale.
Step-by-Step Implementation for Production A2A Endpoints
The following steps cover how to stand up an A2A-compliant endpoint in a production environment.
Step 1: Define the Agent Card. Construct the JSON document covering name, description, url, version, protocolVersion, capabilities, securitySchemes, and skills. Serve it at /.well-known/agent.json through a static file or a GET handler.
Step 2: Implement the JSON-RPC 2.0 endpoint. Accept POST requests at the agent URL. Parse the method field to route message/send, tasks/get, tasks/sendSubscribe, and tasks/cancel to the appropriate handlers.
Step 3: Stand up the task store. A2A servers handle incoming messages as Tasks using a DefaultRequestHandler combined with an InMemoryTaskStore and a custom AgentExecutor that implements execute() to process queries and enqueue completed task events containing artifacts. For production, replace the in-memory store with a persistent backend.
Step 4: Implement SSE streaming. For the tasks/sendSubscribe method, open a persistent HTTP connection with Content-Type: text/event-stream and push TaskStatusUpdateEvent and TaskArtifactUpdateEvent objects as the task progresses. Use append: true and lastChunk: false for intermediate artifact chunks.
Step 5: Configure authentication. Integrate with your enterprise IdP. Declare the scheme in the Agent Card’s securitySchemes field. Validate tokens on every inbound request before task creation.
Step 6: Add observability. Official A2A SDKs for Python and Java include optional OpenTelemetry tracing helpers. Instrument task state transitions, artifact delivery latency, and authentication failures. For load balancing, route by contextId to maintain session affinity across replicas.
How AI Growth Agent Operationalizes A2A at Enterprise Scale
Most organizations understand the A2A protocol conceptually but struggle to operationalize it across a full content and discovery stack. Tooling often ends up fragmented, with one team handling protocol implementation, another handling content production, another handling monitoring, and no unified reporting on outcomes.
AI Growth Agent replaces that fragmented stack with a single engine. Every site AI Growth Agent stands up ships with Agent Card guidance served via /.well-known/, Blog MCP for direct agent interoperability, OpenAI discovery endpoints, natural language query parameters at /?s={query} that return personalized internally linked responses to agents, Markdown served to agent crawlers, and llms.txt and llms-full.txt published so AI surfaces can read the brand in the format they need. None of this requires action from the client, and it ships with every package on day one.
The content layer follows the same level of precision. AI Growth Agent maps the full query universe using real-time Google and ChatGPT data, produces authoritative content validated against primary sources, and publishes it with full schema markup, structured HTML, and protected external linking. This approach creates content that A2A-compliant discovery agents can locate, trust, and cite. Clients average more than 12,000 additional AI citations and mentions across the first twelve weeks, and content can index in as little as ten days.
Organizations no longer need separate protocol implementation, monitoring, and content teams. One engine handles the agentic technical SEO stack, the content production, the self-healing, and the incremental visibility reporting that isolates exactly what the engine generated.

Frequently Asked Questions
How does A2A maintain context across multiple agent interactions?
A2A uses a contextId field to group related tasks across multiple interactions within the same session or workflow. When a client agent initiates a task, it assigns a contextId that the remote agent associates with the conversation thread. Subsequent tasks carrying the same contextId are treated as continuations of the same context, which allows the remote agent to reference prior artifacts, messages, and state transitions without the client re-sending full history. This behavior is distinct from the taskId, which identifies a single discrete task. In long-running multi-agent workflows, the contextId prevents context rot across delegation chains.
What security schemes does the Agent Card support?
Agent Cards declare supported authentication using OpenAPI-aligned security scheme objects. The supported types are apiKey for header or query parameter keys, http for Bearer token or Basic authentication, oauth2 with flows including clientCredentials, authorizationCode, and implicit, openIdConnect for OIDC discovery-based flows, and mtls for mutual TLS certificate authentication. The Agent Card’s securitySchemes object defines the available schemes, and the security array specifies which schemes and scopes are required for each operation. A2A version 1.0 also introduced Signed Agent Cards using JSON Web Signatures for cryptographic identity verification of the agent itself, which is separate from the per-request authentication flow.
Can A2A and MCP be used together in the same architecture?
Yes, and most production enterprise architectures deploy both. A2A handles horizontal agent-to-agent coordination, including discovery via Agent Cards, task delegation, lifecycle management, and SSE streaming between autonomous agents. MCP handles vertical agent-to-tool connections, including structured access to APIs, databases, file systems, and external services. A common pattern uses an orchestrator agent that relies on A2A to delegate sub-tasks to specialist agents, while each specialist agent uses MCP internally to access the tools it needs to complete its task. The two protocols do not conflict because they operate at different layers of the stack. Aligning A2A skill permissions with MCP tool permissions and using delegated tokens is the primary integration consideration for production deployments.
How quickly can an organization achieve A2A-compliant discovery without building infrastructure?
Building A2A infrastructure from scratch, including Agent Card serving, JSON-RPC 2.0 endpoint implementation, SSE streaming, authentication integration, task store, and observability, typically requires several engineering sprints before any content or discovery benefit appears. AI Growth Agent removes that build entirely. The complete agentic technical SEO stack described earlier, including Agent Cards, MCP integration, discovery endpoints, and agent-optimized serving, is live on day one with no engineering hours required from the client. The first article is typically live within one week of kickoff, and content can index in as little as ten days.
Conclusion: Control Brand Narrative Across AI Surfaces
The A2A protocol provides the communication layer that agentic search runs on. Agent Cards at /.well-known/agent.json, JSON-RPC 2.0 task management, SSE streaming, and standardized authentication form the mechanics by which AI agents discover, trust, and cite content at scale. Organizations that expose compliant endpoints with authoritative content become part of the coordination layer, and organizations that do not remain invisible to it.
AI Growth Agent supplies the production engine that operationalizes every layer of that stack without requiring organizations to build or maintain the underlying protocol infrastructure. The agentic technical SEO stack ships with every package. The content is validated, living, and self-healing. The reporting isolates exactly what the engine generated. One engine replaces the fragmented combination of protocol implementation teams, content agencies, monitoring tools, and web infrastructure that most organizations currently stitch together.
The brands cited in AI search this year are training the next generation of models with their own narrative. The window to establish that authority is open now.