Written by: Mariana Fonseca, Editorial Team, AI Growth Agent
Key Takeaways
- AI share of voice replaces traditional rankings by tracking brand mentions, citations, and sentiment inside generative AI responses across platforms like ChatGPT and Gemini.
- A repeatable five-step methodology defines seed queries, captures full AI answers, applies weighted scoring, aggregates percentages, and tracks weekly changes.
- The three-dimension scoring model evaluates position of mention, citation context, and sentiment to create a visibility score that reflects real influence.
- Effective measurement connects directly to content production, earned media distribution, and living updates that drive measurable citation lifts within 60–90 days.
- AI Growth Agent delivers a closed-loop engine that turns weekly AI share of voice data into automated citations and narrative control, so you can schedule a demo to benchmark your brand.
Five-Step Process to Measure AI Share of Voice
Accurate AI share of voice measurement follows five steps in sequence. Each step feeds the next and produces a weighted score that reflects true narrative position instead of raw mention volume.
Step 1: Define the universe of seed terms and long-tail queries. Map every topic cluster relevant to your category using real-time Google and ChatGPT data. Most brands track a handful of head terms and lose the rest of the conversation by default. A mature measurement universe covers hundreds of seed terms and the long-tail queries beneath them, because most B2B brands appear in under 30% of relevant category queries regardless of their conventional SEO rankings.
Step 2: Run queries across target platforms and capture full answer text. Execute each query on ChatGPT, Gemini, Perplexity, and Google AI Mode. Capture the complete response text, not just whether a brand name appears. AI visibility data is volatile, with Google AI Overviews showing 59.3% citation drift and ChatGPT 54.1%, so single snapshots are unreliable. Run queries on a consistent weekly cadence to see real patterns.
Step 3: Apply the three-dimension weighted scoring model. Score each brand mention across position of mention, citation context, and sentiment. The section below walks through the full model and shows how each dimension changes the final score.
Step 4: Aggregate scores into platform-specific and overall AI share of voice percentages. AI Share of Voice % equals the sum of a brand’s weighted scores divided by the sum of all brands’ weighted scores across the query set, engines, and time period. Calculate a separate figure per platform, then create a blended overall score for executive reporting.
Step 5: Track incremental changes week over week. Cross-reference AI share of voice movement with bot tracking data and Google Search Console impressions to isolate which content actions drove visibility shifts. Consistent improvements in AI share of voice typically appear within 60 to 90 days of a focused content and citation strategy, while larger shifts generally require 6 to 12 months.
Measurement without production remains observation only. See how a closed-loop measurement engine maps your full universe and turns data into citations automatically by booking a walkthrough with AI Growth Agent.
Benchmarks for a Strong AI Share of Voice Percentage
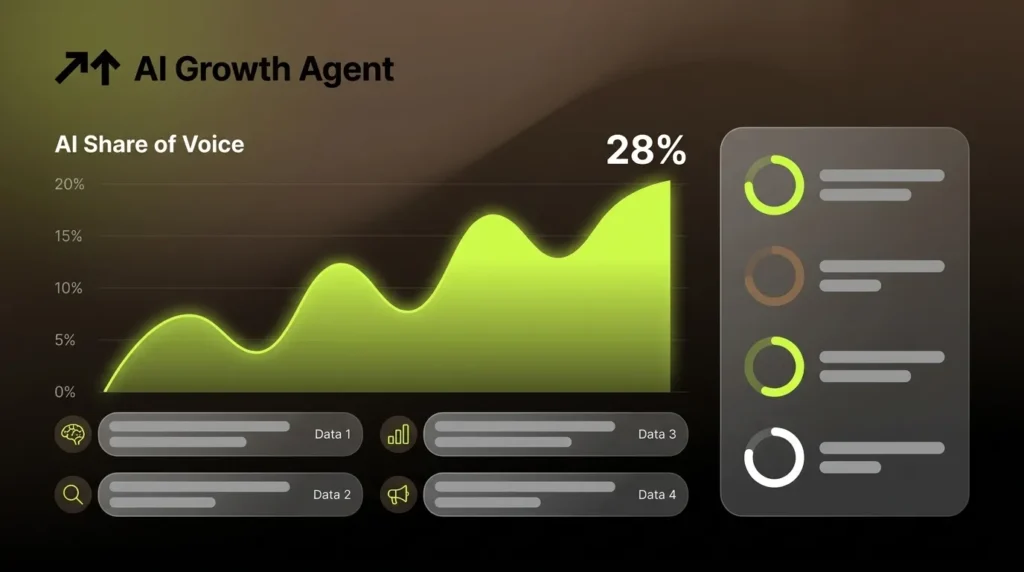
Strong AI share of voice benchmarks depend on category concentration, platform, and competitive set. Recent platform benchmarks vary significantly across Perplexity, ChatGPT, and Gemini for the same brand and query set. Leaders typically achieve 25–45% AI share of voice on their best engine, and in concentrated categories that ceiling rises to 35–50%.
In fragmented markets with many competitors, 15% AI share of voice may represent category leadership, while in consolidated markets with two or three dominant players, falling below 30% means a brand is losing ground. For bottom-of-funnel, solution-aware prompts, below 20% signals a visibility problem, 20–50% indicates an established player present but not dominant, and 50–90% places a brand in category leader territory.
Relative momentum matters more than any absolute figure. A brand improving from 8% to 14% AI share of voice over 60 days signals stronger trajectory than a static 25%.

Two citation-lift data points show what actually moves the needle. Distributing content through third-party news outlets raised citation rate from 8% on a brand’s own site to 34%, a 325% lift. Pages with substantive content updates tend to earn more citations than those with timestamp-only refreshes, and 76.4% of cited pages had been updated within the previous 30 days. Freshness and distribution authority are the two levers with the largest documented impact on AI share of voice percentages. Understanding these benchmarks only creates value when paired with a measurement system that captures the nuances driving them.
Find out where you stand against 2026 category leaders with a free AI share of voice benchmark.
Three-Dimension Weighted Scoring Model for AI Share of Voice
A weighted model produces a strategically meaningful score by treating all three dimensions as separate variables instead of collapsing them into a raw mention count.
Dimension 1: Position of mention. First mention in an AI response carries the highest weight. A weighted AI share of voice model assigns more points when a brand is the primary recommendation or first citation and fewer points when the brand is buried in a longer list. A practical weighting assigns 3 points for first mention, 2 points for second, and 1 point for any subsequent mention.
Dimension 2: Citation context. Context determines whether a mention shapes the answer or merely populates a list. Primary recommendation carries full weight. A supporting citation in a comparison list carries partial weight. A passing reference with no recommendation framing carries minimal weight. GEO share of voice reflects narrative dominance by indicating whether AI uses a brand to explain the category rather than merely mention it. Apply a multiplier of 1.0 for primary recommendation, 0.6 for supporting citation, and 0.3 for passing reference.
Dimension 3: Sentiment. Sentiment in AI answers is measured by tone, qualifiers, tradeoff language, and recommendation framing. Companies holding a high share of mentions often achieve higher sentiment scores than those with lower shares. Apply a sentiment multiplier of 1.2 for positive framing, 1.0 for neutral, and 0.5 for negative.
Example calculation. A brand appears first (3 points) as a primary recommendation (×1.0) with positive sentiment (×1.2) in a single response. The weighted score equals 3 × 1.0 × 1.2, or 3.6. A competitor appears third (1 point) as a passing reference (×0.3) with neutral sentiment (×1.0). The weighted score equals 0.3. Across 100 prompts, sum each brand’s weighted scores and divide by the total weighted scores across all brands to produce the AI share of voice percentage. In CRM studies Salesforce led in raw share of voice but trailed HubSpot in AI sentiment score, which shows that sentiment weighting materially alters the strategic interpretation of visibility metrics.
Limitations of Current AI Visibility Monitoring Tools
Most monitoring tools diagnose where a brand is missing and stop there. They rarely close the loop from measurement to content production to living updates.
HubSpot’s AI content tool caps prompts at roughly 50 and tends to produce content without brand mentions that never rank in AI answers. For HubSpot, AI content is one feature inside a large platform. It monitors competitor visibility but does not create it.
Nightwatch provides AI share of voice tracking with useful benchmark framing, but platforms like these function primarily as data centers without audit or playbook tools, leaving users to determine solutions themselves after identifying issues.
Siftly and Profound track brand appearances for a capped set of prompts. These tools typically lack built-in content creation, authority-building, schema implementation, and strategic guidance, so teams still need separate execution tools and expertise, often requiring 15–25 hours weekly for content production when taking a DIY approach. Profound does not allow users to handle multiple companies from a single account or customize prompts and competitors in detail.
The shared failure across all four tools is the absence of bot tracking, living content production, and incremental visibility reporting. Single-platform AI visibility trackers leave dangerous blind spots because users query across ChatGPT, Perplexity, Google AI Overviews, Claude, and Gemini, which requires multiple tools to approximate full coverage. Monitoring tells you the score. It does not change it.
Closed-Loop Playbook for AI Narrative Control
Measurement turns into narrative control only when it connects directly to content production, living updates, and incremental visibility reporting. The four pillars of Search Intelligence, AI Analytics, Bot Tracking, and AI Ranking create the data foundation that keeps this loop running.
Search Intelligence maps the traditional search landscape, covering positioning, competition, and search volume, and translates raw situation into an actionable diagnosis of where to produce content next. That diagnosis becomes truly useful when paired with AI Analytics, which tracks brand value and consumer behavior across the full journey, from external AI-tool queries through content consumption and sentiment.
Behavior data only matters when you know whether AI models actually read and cite your content. Bot Tracking records every bot interaction, including AI training agents and citation sweeps, so a brand can verify it is being read and cited rather than assuming it. Finally, AI Ranking monitors order of mention and citation context week over week, because AI answers have no static ordered list and position in the answer now functions as the leaderboard.
Content topology connects measurement to production in practice. Earned media consistently drives 84% (range 82–89%) of AI citations across ChatGPT, Claude and Gemini since July 2025, which means authoritative content must be structured for distribution, not just publication. Pages with comparison tables earn 2.5× more AI citations than text-only equivalents, while content with 5–7 statistics earns a 20% higher citation likelihood.
Living content closes the loop between data and outcomes. Content that self-heals and updates over time keeps the brand’s narrative current across training sweeps and citation passes. AI Growth Agent clients average more than 12,000 additional AI citations and mentions, over 100,000 additional bot visits, and a 20%+ lift in impressions across the first twelve weeks. Breadless is now the most recommended healthy franchise in the US ahead of CAVA, Rush Bowls, and Sweetgreen, with ChatGPT citing eatbreadless.com over 45,000 times per month and Google Search Console impressions growing 30× in six months.
Headless marketing architecture removes the headcount requirement from this loop. A single engine handles technical SEO, schema, bot tracking, publishing, and self-healing. The brand decides what to win and the engine executes that plan, with incremental visibility reporting isolating exactly what was generated week over week instead of crediting pre-existing brand visibility.
Frequently Asked Questions
How long does it take to see measurable improvements in AI share of voice?
Consistent improvements typically appear within 60 to 90 days of a focused content and citation strategy. Larger shifts in competitive categories generally require 6 to 12 months. AI Growth Agent publishes the first article within approximately one week of kickoff, with content indexing in as little as ten days. The standard engagement is a three-month pilot, which is enough time to establish a measurable baseline and demonstrate incremental visibility gains week over week.
Who should own AI share of voice measurement inside an organization?
Ownership belongs with the person accountable for marketing outcomes, such as the CMO, VP of Marketing, or the founder acting as chief marketing officer. AI share of voice is a revenue-relevant metric, not a technical SEO task. It connects directly to whether the brand appears in the AI answers that buyers use to make purchasing decisions. Delegating it to an SEO manager without executive ownership leaves the measurement disconnected from content investment decisions and narrative strategy.
What is the difference between AI share of voice and traditional share of voice?
Traditional share of voice measures a brand’s proportional presence in paid media, organic search rankings, or social conversation relative to competitors. AI share of voice measures the percentage and prominence of brand mentions inside generative AI responses, weighted by position of mention, citation context, and sentiment. The key structural difference is that AI answers have no static ordered list. A brand can rank first on Google and be absent from ChatGPT responses entirely, or the reverse. The signals that drive each metric are largely independent, which is why brands need a separate measurement methodology for AI surfaces.
Can AI share of voice measurement scale across hundreds of queries without manual work?
Manual measurement breaks down past a few dozen prompts. A mature AI share of voice universe covers hundreds of seed terms and thousands of long-tail queries beneath them. AI Growth Agent runs more than 3,000 searches every week just to refresh the universe snapshot for mature clients, whose query universes reach 1,600 or more tracked queries. Prompt count is never a billed metric, so the full universe is visible instead of a capped sample. Automated bot tracking, Search Console integration, and weighted scoring replace the spreadsheet workflow entirely.
Why do monitoring tools fail to improve AI share of voice on their own?
Monitoring tools identify where a brand is absent from AI answers but provide no mechanism to change that. They do not produce content, implement schema, track bots at the article level, or connect visibility data to a content production pipeline. The result is a diagnosis without a treatment. Improving AI share of voice requires authoritative content distributed across third-party sources, structured for AI citation, updated frequently, and tracked at the bot level to confirm it is being read and cited. That closed loop requires a production engine, not a monitoring dashboard.
Summary: From Periodic Review to Full Narrative Control
Measuring AI share of voice without producing content remains observation. The weighted scoring model, the five-step methodology, and the four pillars of Search Intelligence, AI Analytics, Bot Tracking, and AI Ranking only create strategic value when they connect directly to authoritative content that earns citations at scale.
Major AI models agree on their top recommendation less than half the time, and perfect consensus across all models occurs rarely. The brands that achieve consistent AI share of voice across platforms are the ones producing the content the models find, trust, and cite, not the ones only monitoring the gap.
Periodic review of weighted scores, citation context, and sentiment trends keeps the measurement methodology calibrated. Review without production, however, leaves the narrative to competitors and random model outputs. The brands cited in AI search this year are training the next generation of models with their own story. The brands that wait are training the next generation with whatever happens to be sitting on the open web.
Traditional search tools show you where your brand stands. AI Growth Agent makes your brand the answer. Schedule a consultation session and see your first article live within a week.