Written by: Mariana Fonseca, Editorial Team, AI Growth Agent
Key Takeaways for AI-Ready Structured Data
- Structured data for AI answers uses JSON-LD markup so AI Overviews and ChatGPT can extract, trust, and cite content by clearly signaling page purpose, authorship, and authority.
- Overview-First formatting with concise lead answers, tables, and lists raises citation rates across ChatGPT, Perplexity, Claude, Gemini, and Google AI Overviews.
- Combining FAQPage, HowTo, Organization, Person, Product, and Article schema with Overview-First formatting can increase AI citation likelihood by 2.5–2.7 times.
- Agentic technical SEO extends schema through Blog MCP, llms.txt, and discovery files so AI agents can act on content beyond traditional search crawlers.
- AI Growth Agent provisions, maintains, and self-heals the full schema stack at enterprise scale while proving incremental citation lift—see the self-healing stack in action.
Overview-First Formatting That Wins AI Citations
AI parsers scan pages for the first coherent answer, score it for entity clarity and factual density, then move on. Concise passages are often cited more frequently than longer passages by ChatGPT, Perplexity, Claude, Gemini, and Google AI Overviews. Lead with the answer in plain language, then support it with detail and evidence.
Tables are the single highest-leverage formatting element for AI citation. Numbered lists and bullet lists can also improve citation rates versus baseline prose, but tables remain the strongest choice when the content supports structured comparison. The table below maps four formatting patterns to their citation performance so you can see how each one helps AI extract answers faster.
| Formatting Pattern | Citation Lift vs. Baseline Prose | Primary Benefit |
|---|---|---|
| Concise lead answer | Often higher citations | Matches LLM extraction window |
| Comparison table | Often higher citations | Structured entity comparison |
| Numbered list | Often higher citations | Sequential clarity for agents |
| Bullet list | Often higher citations | Scannable entity signals |
Pairing Overview-First formatting with explicit entity naming and clean semantic HTML compounds these gains. Pages built with answer-first paragraphs, descriptive headings, and fact-dense sentences tend to be cited more frequently across major AI surfaces. Schema markup amplifies this further: BrightEdge research from early 2026 confirmed the citation multiplier effect mentioned above, finding that the schema combinations most strongly associated with AI Overview citations were Article, FAQPage, HowTo, and Organization, and that sites implementing structured data can see increases in AI search citations.
See Overview-First formatting and schema deployed together from day one.
FAQPage Schema Template for Question-Answer Content
FAQPage markup uses a single FAQPage type per page with a mainEntity array of Question items. Each Question includes a name property holding the full question text and an acceptedAnswer property of type Answer. The visible Q&A text is what AI quotes, while the schema helps systems find, parse, and understand the content, so both layers must be present and must match exactly.
<script type="application/ld+json"> { "@context": "https://schema.org", "@type": "FAQPage", "mainEntity": [ { "@type": "Question", "name": "What is structured data for AI answers?", "acceptedAnswer": { "@type": "Answer", "text": "Structured data for AI answers is JSON-LD markup that signals to AI Overviews and large language models exactly what a page contains, who authored it, and why it is authoritative, enabling extraction and citation in zero-click AI surfaces." } }, { "@type": "Question", "name": "Which schema types most improve AI citation rates?", "acceptedAnswer": { "@type": "Answer", "text": "FAQPage, HowTo, Organization, Person, Product, and Article schema are the highest-impact types for AI citation in 2026, particularly when combined with Overview-First formatting and explicit entity signals." } } ] } </script> Validation steps: Paste the block into Google Rich Results Test and confirm zero errors. Open Search Console, navigate to Enhancements, and monitor the FAQ report for impressions within 30 days. Validation after major schema changes should track rich-result impressions on a 30-day cadence for 90 days, because Google indexing of schema changes can take weeks. All question and answer content must be visible to users on the source page; hidden content that users cannot access via expandable sections is invalid.
Watch automatic FAQPage deployment across your content.
HowTo Schema Template for Step-by-Step Processes
HowTo JSON-LD markup lets Google pull step-by-step guides and feature them directly in search results, which increases the chance of citation in AI Overviews. Use HowTo schema only when the page contains a visible, sequential process that a user can follow. Each step must appear in the rendered page content and must match the schema text exactly.
<script type="application/ld+json"> { "@context": "https://schema.org", "@type": "HowTo", "name": "How to Implement Structured Data for AI Answers", "description": "A step-by-step process for deploying JSON-LD schema that earns citations in AI Overviews and ChatGPT.", "step": [ { "@type": "HowToStep", "position": 1, "name": "Audit existing pages for schema gaps", "text": "Run each target URL through Google Rich Results Test and log which schema types are missing or returning errors." }, { "@type": "HowToStep", "position": 2, "name": "Select the correct schema type", "text": "Match the schema type to the page purpose: FAQPage for Q&A content, HowTo for processes, Product for commerce pages, Organization for brand identity pages." }, { "@type": "HowToStep", "position": 3, "name": "Deploy JSON-LD in the page head", "text": "Add the complete, valid JSON-LD block inside a script tag. Confirm all mandatory properties are present before publishing." }, { "@type": "HowToStep", "position": 4, "name": "Validate and monitor", "text": "Re-run Google Rich Results Test, submit the URL via Search Console URL Inspection, and track Enhancements reports for 90 days." } ] } </script> Pair this block with a numbered list in the visible page body that mirrors each step. Research suggests that pages structured with substantive sections can earn more citations in ChatGPT than pages with very short sections, so each step description should contain enough detail to stand alone.
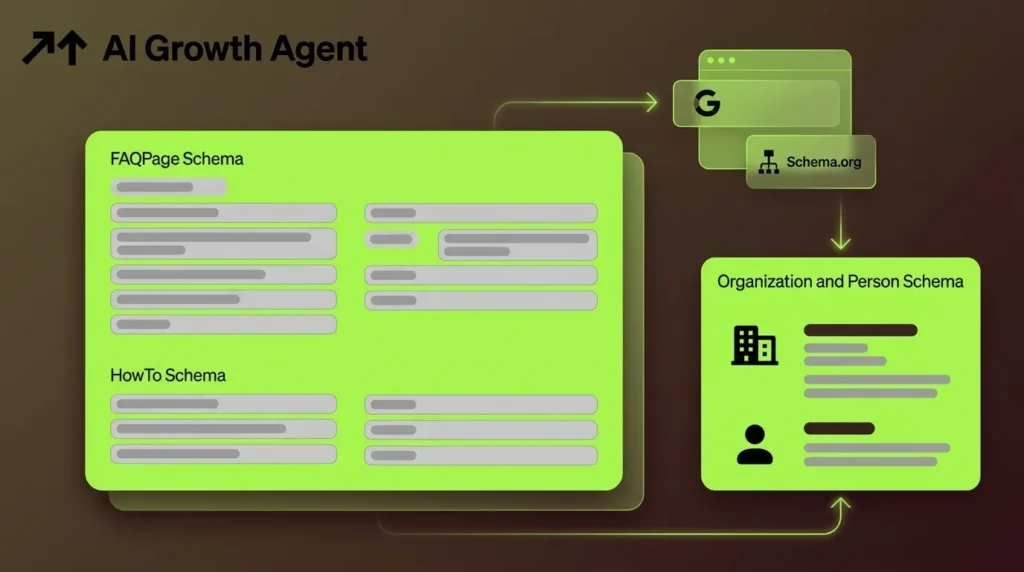
Organization and Person Schema Template for Authority
Organization schema using the “knowsAbout” property establishes a brand as topical authority in Google's Knowledge Graph and reduces confusion with competitors in both Knowledge Graphs and AI citations. Person schema with hasCredential and alumniOf properties demonstrates E-E-A-T at the author level, which AI systems require as E-E-A-T signals for citation in generative search results.
<script type="application/ld+json"> { "@context": "https://schema.org", "@type": "Organization", "name": "Acme Corporation", "url": "https://www.acmecorp.com", "logo": "https://www.acmecorp.com/logo.png", "sameAs": [ "https://www.linkedin.com/company/acmecorp", "https://twitter.com/acmecorp" ], "knowsAbout": [ "Enterprise SaaS", "AI-powered analytics", "B2B revenue operations" ], "founder": { "@type": "Person", "name": "Jane Smith", "url": "https://www.acmecorp.com/team/jane-smith", "hasCredential": { "@type": "EducationalOccupationalCredential", "credentialCategory": "MBA" }, "alumniOf": { "@type": "CollegeOrUniversity", "name": "Stanford University" } } } </script> Organization structured data has no required properties, so site owners should add as many recommended properties as apply, including address, contactPoint, foundingDate, and vatID. Connected structured data in the form of a Content Knowledge Graph enables AI systems to understand entities, relationships, and context at scale, improving brand accuracy and reducing hallucinations in AI-driven experiences. Schema App measured a 19.72% increase in AI Overview visibility on its own site after implementing Entity Linking.
Product and Review Schema Template for Agentic Commerce
AI agents read structured data rather than marketing copy, which makes up-to-date JSON-LD essential for brands that want to remain machine-citable in agentic commerce systems. Gartner predicts that by the end of 2026, 40% of enterprise applications will feature task-specific AI agents, so Product schema now acts as a direct revenue lever, not a technical nicety.
<script type="application/ld+json"> { "@context": "https://schema.org", "@type": "Product", "name": "Acme Analytics Platform", "description": "Enterprise AI analytics platform for B2B revenue operations teams.", "brand": { "@type": "Brand", "name": "Acme Corporation" }, "offers": { "@type": "Offer", "priceCurrency": "USD", "price": "499.00", "availability": "https://schema.org/InStock", "url": "https://www.acmecorp.com/pricing" }, "aggregateRating": { "@type": "AggregateRating", "ratingValue": "4.8", "reviewCount": "312", "bestRating": "5", "worstRating": "1" }, "review": { "@type": "Review", "reviewRating": { "@type": "Rating", "ratingValue": "5" }, "author": { "@type": "Person", "name": "Alex Rivera" }, "reviewBody": "The platform surfaced pipeline gaps we had missed for two quarters. ROI was visible within 30 days." } } </script> LLMs favor brands with more structured data, more third-party mentions, and greater web consensus, which creates recommendation bias that rewards brands with complete, accurate Product schema. Include real-time fields for price, currency, and availability so agent-driven discovery surfaces current information instead of stale data.
Validation Workflow and Bot Tracking for Proven Lift
A complete 2026 structured-data workflow uses two validation tracks. One track covers rich-result validation with Google Rich Results Test, Search Console Enhancements reports, Schema.org validator checks, and manual SERP spot checks. The second track monitors AI citations with manual AI Mode sampling, third-party AI search tools, Knowledge Panel accuracy review, and Wikidata or Google Knowledge Graph API cross-reference checks.
The four-pillar data foundation that AI Growth Agent uses maps directly to this workflow. Search Intelligence identifies which queries are worth targeting with schema, and those queries then feed into AI Analytics, which monitors brand mentions and sentiment shifts. Bot Tracking confirms that AI crawlers reach the schema-enhanced pages that Search Intelligence prioritized, capturing every crawl and citation at the per-article level. AI Ranking then tracks whether those citations gain prominence week over week, replacing the static rank number with a dynamic leaderboard that shows movement. Together, these four pillars prove incremental citation lift instead of attributing pre-existing visibility to new work.
Content updated recently is more likely to be cited by ChatGPT than older pages, so validation cannot remain a one-time event. Teams must re-validate schema after every content update, and bot tracking must confirm that AI crawlers reach the refreshed content.
See how the four-pillar foundation proves citation lift week over week.
Agentic Technical SEO That Extends Schema for AI Agents
Schema markup provides the semantic layer, while agentic technical SEO provides the discovery layer that makes schema machine-actionable for AI agents operating beyond the browser. Schema App built an MCP server so customers can reuse their Content Knowledge Graphs inside AI applications, grounding outputs in accurate, governed information rather than scraped assumptions. Microsoft's NLWeb initiative, built on structured data, enables conversational AI interfaces that let users and AI agents query website content in natural language, which shows how quickly this discovery layer is maturing.
AI Growth Agent was the first to bring Blog MCP to market, with clients running it in the summer of 2025, roughly a year before Google released Web MCP. Every site ships with Blog MCP endpoints that expose schema, manifest, and capability guidance to agents, which forms the discovery layer. Once an agent discovers the site, OpenAI-specific guidance served via /.well-known/ tells it how to query the content. Natural language query parameters at /?s={query} then let the agent pass questions directly into the URL and receive personalized, internally linked responses. To keep compatibility high across different agent architectures, pages are served in Markdown to agent crawlers, and llms.txt plus llms-full.txt provide a structured content index so AI surfaces can navigate the brand's knowledge base efficiently.
These files do not replace schema, because schema still carries the semantic meaning. They extend it. A brand with complete JSON-LD but no llms.txt or MCP endpoint remains visible to search crawlers and only partially visible to AI surfaces. A brand with the full agentic stack becomes readable, queryable, and citable for every layer of the AI discovery chain at the same time.
Frequently Asked Questions About Enterprise Deployment
The technical foundation is now clear. The questions below address the practical realities teams face when moving from theory to implementation, including timelines, ownership, integration, and the citation variability that shapes ROI.
How long does it take to implement structured data for AI answers at enterprise scale?
Implementation timelines depend on site size, CMS architecture, and the number of schema types required. For a mid-market site of 150 to 500 pages, a complete JSON-LD deployment covering FAQPage, HowTo, Organization, Person, Product, and Article schema typically takes two to four weeks when managed manually by an in-house team or agency. AI Growth Agent provisions the full schema stack automatically as part of site setup, with the first article live in about one week and content indexing in as little as ten days. Validation cadence runs on a 30-day cycle for 90 days after any major schema change, because Google indexing of schema updates can take several weeks to appear in Search Console Enhancements reports and AI citation monitoring.
Who owns and maintains the schema once it is deployed?
In a traditional setup, schema ownership fragments across the CMS team, the SEO agency, and the web development vendor, which slows updates and lets schema drift out of sync with page content. AI Growth Agent transfers full ownership to the client. The site, the content, and the schema stack all remain client-owned assets. The engine self-heals schema as content updates, so markup never falls out of sync with visible page text, which remains a hard requirement for FAQPage and HowTo eligibility. No agency dependency appears, and no engineering hours are required from the client side to maintain the stack.
How does structured data integrate with the rest of the agentic technical SEO stack?
Structured data forms the semantic foundation, and the agentic layer sits on top of it. That agentic layer includes Blog MCP, llms.txt, llms-full.txt, and /.well-known/ discovery files that make schema machine-actionable for AI agents operating outside the traditional crawl-and-index cycle. Without valid, complete JSON-LD, the agentic layer has no structured information to expose. Without the agentic layer, schema remains readable only by search crawlers and not by the agents that increasingly mediate purchasing and recommendation decisions. The integration step on the client side uses a single reverse proxy rewrite that connects the blog to a subdirectory under the brand's domain, and everything else, including the full schema suite, MCP endpoints, llms.txt, and /.well-known/ files, ships automatically with every AI Growth Agent package.
How much citation variability should brands expect after deploying structured data?
Citation rates vary by industry, query type, content freshness, and the competitive density of the schema landscape in a given topic area. Brands in categories with high third-party mention volume, such as consumer products with active review ecosystems, tend to see faster citation lift than B2B brands in narrow verticals. Most brands see measurable changes in citation frequency within 30 to 45 days after implementing content structure and schema changes, with Perplexity reflecting changes fastest because it uses live web pulls. AI Growth Agent clients average more than 12,000 additional AI citations and mentions across the first twelve weeks, alongside more than 100,000 additional bot visits and a 20% or greater lift in impressions. Individual results vary: Breadless reached over 45,000 ChatGPT citations per month for eatbreadless.com, while Leva Sleep exceeded 10,000 ChatGPT citations per month within a comparable timeframe. The four-pillar data foundation isolates incremental citation lift from pre-existing brand visibility so measurement reflects what the schema and content work actually generated.

Conclusion: Turning Schema Into AI Narrative Control
Structured data for AI answers now acts as the foundation of narrative control in a zero-click world where AI surfaces shape customer beliefs before a visit. FAQPage, HowTo, Organization, Person, and Product schema, deployed correctly, validated continuously, and extended with agentic technical SEO, determine whether a brand appears as a cited source or remains invisible when a customer asks the question that matters most.
The brands winning AI citations in 2026 are not always the ones with the largest budgets or the most content. They are the brands with the most parseable, trustworthy, and machine-actionable information on the open web. That reality requires a system, not a plugin, and a system that self-heals instead of going stale the day it ships.
AI Growth Agent is the only headless engine that delivers the self-healing schema architecture described above, integrated with agentic technical SEO and validated against the four-pillar data foundation. Traditional search tools show you where your brand stands. AI Growth Agent makes your brand the answer.
Schedule a consultation session and see your first article live within a week.